6. Parallel Computing Toolbox の利用¶
運用終了
TSUBAME3 は既に運用を終了しています。 TSUBAME4 のマニュアル類はこちら
6.1. Parallel Computing Toolbox について¶
Parallel Computing Toolbox の主な機能は次の通りです。
- パラレル for ループ (parfor) によるマルチプロセッサでのタスク並列アルゴリズムの実行
- CUDA に対応した NVIDIA GPU のサポート
- ローカルのマルチコア デスクトップで 12 ワーカーまで起動可能
- 大規模データ セットの処理とデータ並列アルゴリズムに対応する分散配列および spmd (Single Program Multiple Data) 構文
複数のワーカーによる並列処理を行うことで計算時間が短縮するメリットがあります。
また、GPU計算がサポートされているため、GPU を使用した演算が可能です。
詳細な内容は、Mathworks 社のホームページや、MATLAB のヘルプ機能をご参照ください。
6.2. 並列処理¶
ここでは、Parallel Computing Toolbox による並列処理の 基本的な利用方法を説明します。
次のような、sin カーブをプロットするコードについて考えます。
for i=1:1024
A(i) = sin(i*2*pi/1024);
end
plot(A)
このコードを並列処理する方法を説明します。
並列処理を行うためには、ワーカーを起動しておく必要があります。 ここでワーカーとは、MATLAB セッションとは別に動作するMATLAB 計算エンジンのプロセスのことで、 ワーカーを使用する関数を用いることで各ワーカープロセスに処理を割り振ることができます。 ワーカーの起動には parpool 関数を使用します。
>> parpool('local', 4)
Starting parallel pool (parpool) using the 'local' profile ... connected to 4 workers.
第2引数の「4」は起動するワーカーの数で、最大「12」まで指定できます。
並列処理を行うようにコードの修正を行います。 違いは、「for」の代わりに「parfor」を用いることだけです。
parfor i=1:1024
A(i) = sin(i*2*pi/1024);
end
plot(A)
ワーカープロセスを終了する場合は、次のコマンドを実行します。
>> poolobj = gcp('nocreate');
>> delete(poolobj)
Parallel pool using the 'local' profile is shutting down.
6.3. GPU を使用した演算¶
MATLAB R2010bから「Parallel Computing Toolbox」のGPUコンピューティング対応されています。 GPU とのデータのやり取りを意識する必要があり 主な手順としては次のようになります。
- GPUメモリに送信
- GPU上で計算
- GPUから結果を回収
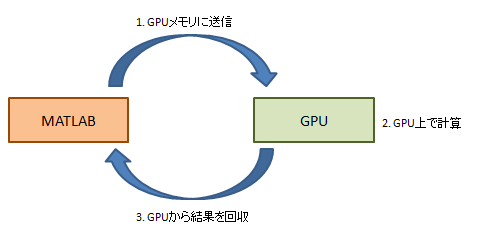
GPU 演算の流れを実際の計算例を使って示します。
この例ではGPU のメモリ上にデータを送信する関数「GPUArray」と、 GPU 上の結果をメインメモリへ回収する関数「gather」を用いています。 また、fft2 関数は GPU 計算に対応しており使用例を示します。
>> N = 6;
>> M = magic(N) ← 行列 M を作成
M =
35 1 6 26 19 24
3 32 7 21 23 25
31 9 2 22 27 20
8 28 33 17 10 15
30 5 34 12 14 16
4 36 29 13 18 11
>> G1 = gpuArray(M); ← GPU メモリに送信
>> G2 = fft2(G1); ← fft2 を GPU 上で実行
>> M1 = gather(G2) ← 結果をメインメモリを回収
M1 =
1.0e+02 *
6.6600 + 0.0000i 0.0000 + 0.0000i 0.0000 - 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i
0.0000 + 0.0000i 0.7200 + 0.3118i -0.2700 - 0.4677i -0.3600 + 0.6235i 0.5400 - 0.0000i -0.6300 - 0.4677i
0.0000 + 0.0000i 0.0000 + 0.0000i 0.5400 + 0.3118i 0.0000 + 0.0000i 0.0000 - 0.2078i 0.0000 + 0.0000i
0.0000 + 0.0000i 0.4500 + 1.0912i 1.3500 + 0.4677i 1.2600 + 0.0000i 1.3500 - 0.4677i 0.4500 - 1.0912i
0.0000 + 0.0000i 0.0000 - 0.0000i 0.0000 + 0.2078i 0.0000 + 0.0000i 0.5400 - 0.3118i 0.0000 + 0.0000i
0.0000 + 0.0000i -0.6300 + 0.4677i 0.5400 + 0.0000i -0.3600 - 0.6235i -0.2700 + 0.4677i 0.7200 - 0.3118i
>> M2 = fft2(M) ← CPU のみで計算した場合。GPU での計算結果と同じになることが確認できる。
M2 =
1.0e+02 *
6.6600 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i 0.0000 + 0.0000i
0.0000 - 0.0000i 0.7200 + 0.3118i -0.2700 - 0.4677i -0.3600 + 0.6235i 0.5400 + 0.0000i -0.6300 - 0.4677i
0.0000 + 0.0000i 0.0000 + 0.0000i 0.5400 + 0.3118i 0.0000 + 0.0000i 0.0000 - 0.2078i 0.0000 + 0.0000i
0.0000 + 0.0000i 0.4500 + 1.0912i 1.3500 + 0.4677i 1.2600 + 0.0000i 1.3500 - 0.4677i 0.4500 - 1.0912i
0.0000 - 0.0000i 0.0000 + 0.0000i 0.0000 + 0.2078i 0.0000 + 0.0000i 0.5400 - 0.3118i 0.0000 + 0.0000i
0.0000 + 0.0000i -0.6300 + 0.4677i 0.5400 + 0.0000i -0.3600 - 0.6235i -0.2700 + 0.4677i 0.7200 - 0.3118i
なお、GPU 対応している関数の一覧を得るには次のコマンドを実行します。
>> methods('gpuArray')
Methods for class gpuArray:
abs csch im2int16 lsqr sec
accumarray ctranspose im2single lt secd
acos cummax im2uint16 lu sech
:(以下略)
個々の関数のヘルプを参照するには次のコマンドを実行します。
>> help gpuArray/functionname
mtimes関数の場合は次のようになります。
>> help gpuArray/mtimes
* Matrix multiply for gpuArray
C = A * B
C = MTIMES(A,B)
64-bit integers are not supported.
Example:
N = 1000;
A = gpuArray.rand(N)
B = gpuArray.rand(N)
C = A * B
See also MTIMES, GPUARRAY.
6.4. 複数ノードの使用¶
Warning
matlabのプラグインの仕様上、複数ノードでの実行はf_nodeでしか動作しません。
. /apps/t3/sles12sp2/uge/latest/default/common/settings.sh
を実行してからmatlabを起動して下さい。
matlab内で計算用のジョブをさらに発行するため、matlabを起動する際に確保する資源は-l s_core=1などの小さいもので構いません。
複数ノードを使用して並列計算を行うには以下の設定を行う必要があります。
- Home -> Parallel -> Create and Manage Clustersを選択
- Add Cluster Profile -> Genericを選択
- Editを選択し、SCHEDULER PLUGINの設定でPluginScriptLocationに
/apps/t3/sles12sp2/isv/matlab/plugins/matlab-parallel-gridengine-pluginを入力 - AdditionalPropertiesのNameに
AdditionalSubmitArgs、Valueに-g <グループ名> -l h_rt=<時間> -l f_node=<ノード数>を入力 - Validateを選択し、Numbers of workers to useにノード数x28(例:f_node=2の場合は56)を入力し実行、設定したノード数で実行できるか確認。全てPassedになっていれば正しく設定されている
- Validateをパスしたら、Parallel -> Select Parallel Environment -> CLUSTERから先ほど作成したプロファイルを指定
parpool(N)
でジョブが投入され、ジョブが流れると
Starting parallel pool (parpool) using the 'GenericProfile1' profile ...
Connected to parallel pool with N workers.
と表示され、複数ノードでの実行が可能となります。